We present an online reinforcement learning (RL) algorithm for fine-tuning flow-matching policies in continuous-control problems. Our key insight is to view RL-based policy improvement as a transport of action densities towards regions of high reward, which naturally aligns with the transport formulation of flow matching models.
Prior methods either approximate the current or optimal policy distribution or resort to distillation, which introduces biased gradients or sacrifices multimodal modeling capacity. In contrast, our approach — Reinforcement Learning with Density Transport (RLDT) — constructs a transport field from a maximum-entropy RL objective using Stein Variational Gradient Descent (SVGD), then fine-tunes a pretrained flow matching policy to align with this field.
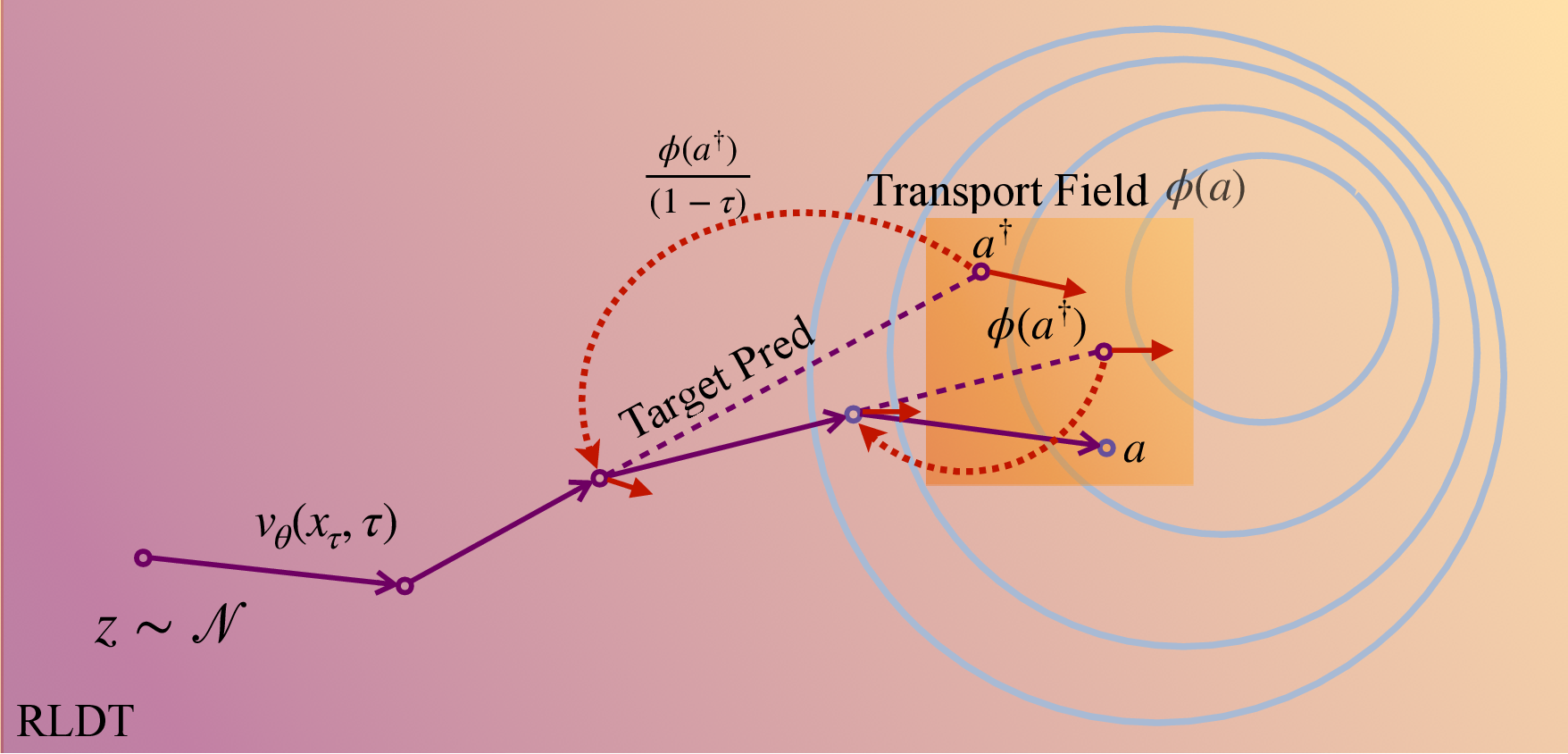
Training with this alignment objective is nontrivial because flow-matching policies generate actions via a multi-step process, making direct gradient-based optimization challenging. To overcome this challenge and stabilize training, we approximate policy actions from intermediate denoising steps via expected-target estimation. This allows the transport-field update to propagate into the network parameters without unstable backpropagation through time.
Experimental results demonstrate that RLDT outperforms competitive baselines in reward quality and convergence speed. This performance holds across diverse continuous-control tasks, encompassing both dense and sparse rewards, as well as state- and vision-based long-horizon robot manipulation.
RLDT recasts RL policy improvement as a probability transport problem on the action manifold. A flow-matching policy first maps Gaussian noise to an action distribution; RLDT then steers that distribution toward high-reward regions without collapsing its multimodal structure.
A flow-matching policy maps Gaussian noise to a bimodal action distribution; the RL challenge is that the resulting samples spread over action space and miss the reward peaks.
RLDT constructs a transport field $\phi^*(a)$ via SVGD that combines two forces: an attractive term pulling samples toward high-reward regions of the Q-function, and a repulsive kernel term that prevents particle collapse and preserves diversity. The animation below shows how these two components interact to move action samples onto the reward peaks while keeping them spread across both modes.
The SVGD field decomposes into Q-gradient attraction (orange) and kernel repulsion (blue); their combination $\phi^*$ (yellow) moves particles to reward peaks without mode collapse.
Because flow-matching generates actions over many ODE steps, backpropagating gradients through the full denoising chain is unstable. Instead, RLDT maps each intermediate denoising sample $a_{t,\tau}$ to its expected posterior $a^\dagger_{t,\tau}$ — a predicted final action that lies on the action manifold. Applying the transport field to $a^\dagger$ induces a proportional update in the velocity network $v_\theta$, propagating reward signal across all ODE steps without a reverse ODE.
The expected target $a^\dagger_{t,\tau}$ (pink diamond) projects any intermediate denoising state onto the action manifold; the transport field applied there back-propagates stably into the network without unrolling the ODE.
The policy is updated with three losses: an RL loss that aligns the velocity field with the transport direction $\phi^*(a^\dagger)$; a consistency loss that keeps flow trajectories straight by penalizing the gap between $a^\dagger_{t,\tau}$ and the final action sample; and a constraint loss (Fisher divergence from the frozen pretrained policy) that prevents the policy from drifting too far during fine-tuning. The animation below summarizes the full pipeline.
Full RLDT pipeline: sample noise → flow matching → expected target $a^\dagger$ → SVGD transport $\phi^*$ → update $\theta$.
We evaluate RLDT across three benchmark settings of increasing complexity: dense-reward locomotion (OpenAI Gym — Walker2d, Hopper, HalfCheetah), long-horizon sparse-reward manipulation (Furniture-Bench — One-Leg and Lamp with Low/Medium randomness), and vision-based robot manipulation (Robomimic — Square and Transport). We compare against DPPO, ReinFlow, FPO++, and QAM.
RLDT achieves the highest rewards across all Gym baselines by a significant margin. DPPO results match those reported in the original paper, while ReinFlow underperforms on HalfCheetah and Hopper. QAM performance varies across tasks but always underperforms RLDT.

Dense reward tasks on OpenAI Gym. Mean and standard deviation over 3 seeds.
On Robomimic (Square), RLDT starts with a higher initial success rate and reaches ~90%. On Transport, RLDT converges to performance comparable to DPPO while ReinFlow significantly underperforms. On the challenging Furniture-Bench Lamp-Med task, RLDT reaches ~70% success rate versus DPPO's ~30%.

Sparse reward tasks. Left: state-based Robomimic benchmark. Right: Furniture-Bench manipulation tasks. Averaged over 3 seeds.
Prior approaches to RL for diffusion and flow-matching policies include:
DPPO, ReinFlow and FPO optimize lightweight lower bounds on the policy log-likelihood, which leads to biased policy gradients.
QAM solves the reverse ODE to obtain per-step adjoint targets, incurring sensitivity to ODE solver accuracy.
RLDT differs by constructing a transport field directly on the action manifold, enabling principled gradient propagation without density estimation or architectural constraints.